
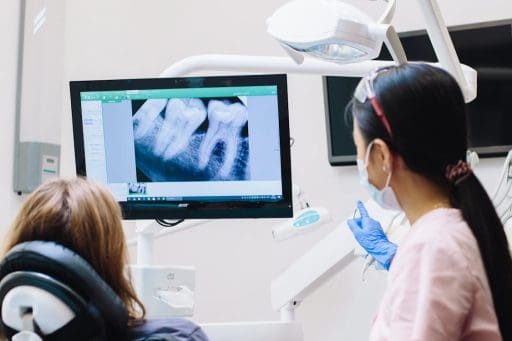
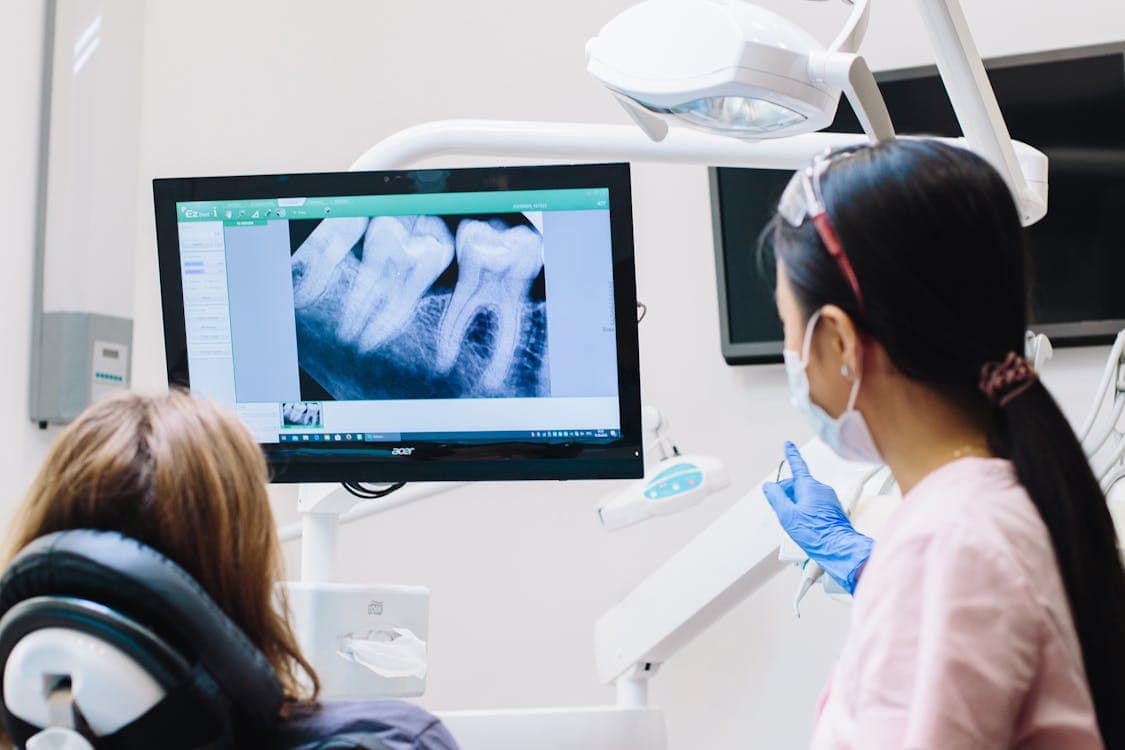
Artificial vision tools have moved from a nascent curiosity to a regular part of many workflows, and the question of error reduction is front and center. Human practitioners bring judgment and context while machines bring scale and repeatable patterns, so their interplay can shift outcomes in subtle ways.
The gap between a quick glance and a careful read of a file is where mistakes creep in, and new tools try to tighten that gap with algorithms that spot patterns humans might overlook.
The Nature Of Human Error In Image Analysis
Errors in visual tasks often come from fatigue and routine that dull sharpness of attention after long hours of review. Perceptual biases make some features pop while others fade into the background, turning a clear image into a partial story.
Analysts sometimes rely on heuristics that speed work but introduce systematic misses, much like trusting a familiar route that has a pot hole. Small slips can cascade when one miss leads to another, so error is not just isolated but contagious in workflows.
How AI Systems Approach Visual Tasks
Machine vision models learn from many labeled examples and extract statistical regularities that are hard for a single human to hold in mind. These models build layers of features and then match patterns across new images, often catching faint cues under noise or poor lighting.
Training tunes the model to prefer certain visual ngrams that correlate with a target label, and repeated exposure refines that tendency. In fields like medical imaging, many teams now seek solutions built by people who know imaging, since domain expertise often shapes models that behave more reliably in clinical settings. The process can be blunt at times, yet it is relentless and consistent in ways people rarely are.
Strengths Of AI In Reducing Mistakes

One big strength is consistency because an algorithm will apply the same rule set every time it inspects a pixel array, free from end of day tiredness. When trained on diverse cases it can flag rare anomalies that a single reviewer might skip, turning a needle in a haystack into a highlighted item.
Automation can triage large batches so a human only checks hard calls, which often cuts down on routine misses. Speed also plays a role since faster cycle times permit more checks without burning out the team.
Limitations And New Types Of Errors Introduced
Models can be brittle when they encounter data that fall outside their training distribution, leading to confident yet wrong answers that are hard to spot. Bias in training examples creates blind spots and systematic skew that repeat the same error across many instances.
Overreliance on a model’s top prediction can turn a safety net into a single point of failure, and false positives generate wasted work that erodes trust. In practice the machine and the human create a new error ecology that requires careful shaping.
The Role Of Training Data Quality
Garbage in often yields garbage out when labels are inconsistent or exemplars do not reflect operational reality, and the model will inherit those flaws. Curated, well labeled, and diverse sets help the model learn robust cues rather than spurious correlations that break in the wild.
Active sampling strategies that surface edge cases for human review improve the training loop and shrink blind spots over time. Data curation is time consuming, yet it is a linchpin for better model behavior.
Human In The Loop Collaboration Models
Keeping a human decision maker in the loop blends the best of both worlds where the algorithm handles scale and the person brings nuanced judgment. Workflow designs that let the model propose and the human confirm reduce both miss rates and false alarms, akin to having an extra pair of eyes on tricky items.
Escalation paths for uncertain cases and easy ways to correct the model feed back into continuous learning. When teams share accountability the tendency to blindly trust a single source drops and vigilance stays higher.
Evaluation And Monitoring For Real World Use
Benchmark tests are a start but they can hide failure modes that crop up after deployment when conditions shift or rare classes appear. Continuous monitoring that tracks error rates, drift in input statistics, and shifts in label meaning helps teams spot decay before it becomes costly.
Periodic audits with fresh human labels reset the baseline and reveal where the model has gone astray. Metrics should be practical and tied to operational harm so that a rise in small errors does not go unnoticed.
Regulatory And Ethical Considerations
Regulators are asking for transparency in how vision systems reach decisions and for mechanisms that let humans override automated calls when stakes are high. Privacy rules and consent regimes shape what training data can be used and how outputs are governed in sensitive domains like health care.
Ethical review boards and clear documentation of failure modes help keep processes honest and accountable when humans are not in the loop for every item. Good governance encourages safer deployment and reduces the risk that automation amplifies harm.
Scaling Best Practices Across Teams
Shared playbooks about when to trust the model and when to escalate build a common language between developers and operators, which lowers the chance of misaligned expectations. Training sessions that reveal model quirks through examples teach analysts to spot typical pitfalls and to spot confident errors that look wrong to the naked eye.
Iterative feedback loops that route corrections back into retraining pipelines close the gap between the model and the domain experts. Over time the ensemble of human knowledge plus model outputs becomes stronger than either part alone.
Future Directions For Safer Image Analysis
Research on interpretable models and on methods that quantify uncertainty helps people decide when to trust a machine suggestion and when to bring a colleague into the loop. Hybrid systems that combine symbolic rules with neural pattern matchers show promise for capturing both hard constraints and fuzzy visual cues.
Community driven benchmarks with real world variability push models toward resilience and reveal where extra human checks are still needed. The path ahead looks like gradual refinement, lots of testing, and an ongoing partnership between machines and humans where two heads are better than one.








